(この記事は、Hadoop Advent Calender 2013 の12日目の記事です)
こんにちは、Amebaのログ解析基盤Patriotの運用をしている、鈴木(@brfrn169)と柿島です。
Patriotについては以下をご覧ください。
http://ameblo.jp/principia-ca/entry-10635727790.html
http://www.slideshare.net/cyberagent/cloudera-world-tokyo-2013
今回、Amebaのログ解析基盤PatriotにCloudera ImpalaとPrestoを導入しました。
Cloudera ImpalaとPrestoのインストール方法や詳細ついては、下記URLをご覧ください。
Cloudera Impala
http://www.cloudera.com/content/cloudera-content/cloudera-docs/Impala/latest/
Presto
http://prestodb.io/
インストールは、基本的にはドキュメントに従って実施しました。
一箇所だけハマったのが、PrestoでのHDFSのHAの設定方法です。
etc/catalog/hive.propertiesに以下を追加する必要があります。
| hive.config.resources=/etc/hadoop/conf/core-site.xml,/etc/hadoop/conf/hdfs-site.xml |
上記対応は、以下のURLを参考にしました。
https://github.com/facebook/presto/issues/845
なぜ、似たような用途、アーキテクチャのCloudera ImpalaとPrestoの両方を本番に導入したのかと思われるかもしれないのですが、いくつか理由があります。
(1)両者ともに成長中のミドルウェアであるため、私たちの利用する観点で機能を比較したとき、それぞれにメリット、デメリットがありました。
(2)検証環境でも試しているのですが、低スペックなマシン、少ないデータでの検証結果だけで、どちらか一方の本番導入を決めるよりも、本番環境のスペック、大量データで実際に両者を使用して比較をしたほうがよいと考えました。
(3)アナリストの方に触ってもらい意見を聞きながらよりよいほうを選択していきたいと思っています。
(1)機能について
基礎的な項目+α(私たちが重要と考えた項目)について比較していきます。
(ソースはまだ読めてないので、基本ドキュメントベースとドキュメントで見つからないものは実際に動かしての比較になります)
共通項目
・SQLに似た言語を使用可能
・MapReduceを用いないので、低レイテンシで対話的にデータの探索的な分析ができる
・両方インメモリで処理を行うので、割当てメモリの制限を受ける
| Cloudera Impala | Presto | |
|---|---|---|
| 開発言語 | C++ | Java |
| ライセンス | Apache License | Apache License v2 |
| 接続インターフェース |
|
|
| 対応データ型 |
※maps, arrays, structsなどは対応していない (SELECTもエラーになる) |
データ型の詳細について、表の下で別途まとめる |
| 対応しているステートメント |
|
※ CREATEやINSERTなどは未対応 |
| ビルトイン関数 | こちら | こちら ※Cloudera Impalaの対応していないWindow FunctionやJSON Functionに対応している |
| UDFサポート | サポート(1.2.0以上) | 未サポート |
| Hiveでデータ更新後 のメタ情報の更新 |
メタ情報のキャッシュをするため、メタ情報を更新するためには、REFRESH(既存テーブル)、 INVALIDATE METADATA(新規テーブル)の実行が必要 ※1.2.1のCatalogdの導入からCloudera Impala経由での更新については自動更新 |
ドキュメントには書いてないが、少しの時間差を伴って自動更新されるように見える |
| 耐障害性 | SPOFなし ※impala-serverがダウンした場合はクエリが失敗する、statestoreが死んだ場合はホスト情報の更新ができなくなる |
ドキュメントにはのってないように見えるので、coordinator兼discovery-serviceを落としてみたところ、クエリの処理が停止、新しく接続するcoordinator兼discovery-serviceはいないので、SPOFに見える。 ※ それぞれが複数立てれるかは未検証 |
Prestoのデータ型変換について
Hive側で以下のテーブルを作成しました。
create table test ( a TINYINT, b SMALLINT, c INT, d BIGINT, e FLOAT, f DOUBLE, g DECIMAL, h TIMESTAMP, i STRING, j BOOLEAN, k ARRAY<INT>, l MAP<STRING, INT>, m STRUCT<col1 : INT, col2: STRING> ); |
Presto側では、このテーブルの各カラムの型は以下のように見えます。
presto:default> desc test; Column | Type | Null | Partition Key --------+---------+------+--------------- a | bigint | true | false b | bigint | true | false c | bigint | true | false d | bigint | true | false e | double | true | false f | double | true | false h | bigint | true | false i | varchar | true | false j | boolean | true | false k | varchar | true | false l | varchar | true | false m | varchar | true | false |
今回試した数種類のカラムは、Prestoではboolean, bigint, double, varchar の4つのいずれかの型として扱われました。
両者のARRAY型、MAP型、STRUCT型の扱いについて
Hive上でデータをINSERTした後、Cloudera Impala, PrestoそれぞれでこのテーブルをSELECTすると以下のようになります。
Cloudera Impalaの場合(エラーになる)
> select * from test; Query: select * from test ERROR: AnalysisException: Failed to load metadata for table: default.test CAUSED BY: TableLoadingException: Failed to load metadata for table 'test' due to unsupported column type 'array<int>' in column 'k' |
ARRAY型, MAP型, STRUCT型を含んでいるとSELECTもできません。
Prestoの場合(SELECTできる)
presto:default> select * from test; a | b | c | d | e | f | h | i | j | k | l | m ---+---+---+---+-----+-----+---+------+------+---------+---------------------+----------------------- 1 | 1 | 1 | 1 | 1.0 | 1.0 | 0 | true | true | [1,2,3] | {"b":2,"a":1,"c":3} | {"col1":1,"col2":"a"} (1 row) |
Prestoでは、ARRAY型, MAP型, STRUCT型の3つもvarchar型として扱われ、Impalaと違いエラーにはなりません。
(補足)varcharは中の値に対しても関数を使うことで、個々の値にアクセスが可能となっています。
presto:default> select json_extract_scalar(k,'$[0]'), json_extract_scalar(l,'$.b'), json_extract_scalar(m,'$.col1') from test; _col0 | _col1 | _col2 -------+-------+------- 1 | 2 | 1 |
私たちの環境にはARRAY型, MAP型のカラムを持つテーブルが多く存在するので、型の情報は変わってしまってもSELECTできるPrestoは魅力的です。
※Cloudera Impalaでもバージョン2.0では、ARRAY型,MAP型のサポート予定があるそうです
(2)環境について
導入した環境ではCDH、Cloudera Impala, Prestoの各プロセスは下図のようにマスター系3台とワーカー系28台にわかれて起動しています。
Image may be NSFW.
Clik here to view.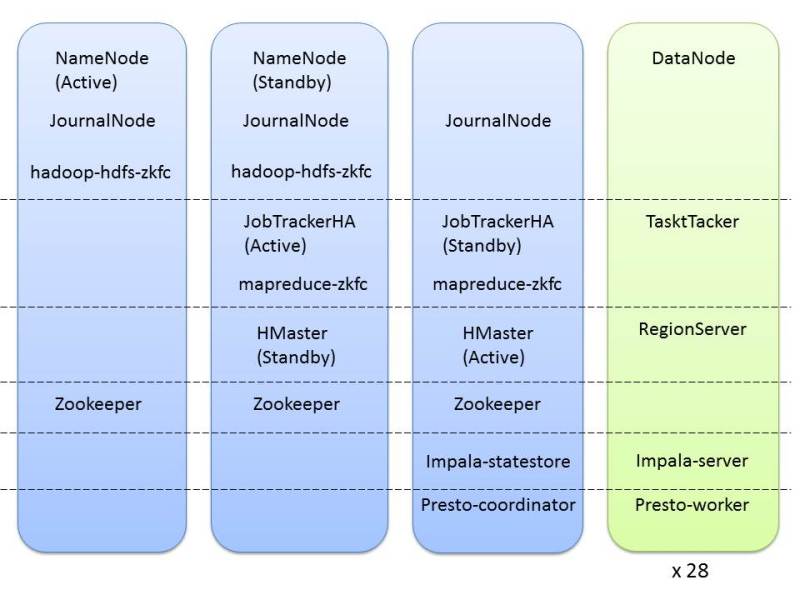
バージョンは以下の通りです。
・CDH 4.3.0
・Cloudera Impala 1.1.1
・Presto 0.54
検証環境では、CDH4.5.0やCloudera Impala1.2.1も検証中ですが、Hiveのバグを踏んだり、impala-catalogdの起動後、hive-metastoreが死んだりと不安定になる現象が発生したので、本番は上のバージョンで動かしています。
DataNodeを起動しているサーバのスペックは
・CPU Intel(R) Xeon(R) CPU E5-2650L 0 @ 1.80GHz * 2
・ディスク SATA 3TB × 12本(JBOD), SAS300GB * 2 (RAID1)
・メモリ 96GB( メモリの内訳は DataNode 4GB, TaskTracker 1.5GB, RegionServer 8GB, Cloudera Impala 5GB, Presto 5GB, その他 MapReduceのスロット用、OS用となっています)
また、Cloudera Impala, Prestoを両方稼働するためにそれぞれに割り当て可能なメモリ量が5GBと少なくなっています。
実際にクエリを流してみた結果
上記環境で、いくつかのパータンの結果を一例として紹介させていただきます。
※ 本番クラスタなので他(Flumeや他のMapReduce)からの影響を受けている可能性があるので、それぞれ3回実施した平均値を記載しています。
| 処理内容 | Cloudera Impala | Presto | Hive |
|---|---|---|---|
| 約1GB 約40,000,000行 SELECT COUNT | 6 | 5 | 95 |
| 約1GB 約40,000,000行 GROUP BY | 13 | 7 | 101 |
| 約1GB 約40,000,000行 ORDER BY LIMIT 100 | 16 | 114 | 213 |
| 約1GB 約40,000,000行 JOIN 約800MB 約40,000,000行 GROUP BY | 44 | 166 | 385 |
雑感
・ふれこみ通り、Hiveに比べれば両者とも数倍から10数倍程度の実行時間の差がありました。
・私たちが試したケースでは、複雑なクエリではCloudera Impalaのほうが速く処理を終えることが多かったです。
・両者を比較するために試すクエリが弊社でよく使っているARRAY型, MAP型を含まないものに限られてしまったことは残念に感じました。
(3) アナリストに実際に使ってもらった感想
・Presto CLI は結果画面がlessに渡してくれるのが便利
・Presto CLIの実行画面はCloudera Impalaに比べて進捗状況がわかりやすい
(3) アナリストに実際に使ってもらった感想
・Presto CLI は結果画面がlessに渡してくれるのが便利
・Presto CLIの実行画面はCloudera Impalaに比べて進捗状況がわかりやすい
・Prestoは単純なクエリの場合だと爆速感がありますが、group by とか関数使うとそんなに速くない印象を受けました。
・(Hiveに比べて)両者とも、headっぽい(SELECT LIMIT 10のような)使い方が爆速にできるのは非常にありがたくて、分析の思考を止めること無く素早くクエリを作り上げることができそうです。
今回、ログ解析基盤 PatriotにCloudera ImpalaとPrestoを導入しました。
現在のところ、PrestoもCloudera Impalaも一長一短なので、しばらくは併用しながら両者の動向を追っていきたいと思っています。
弊社ではARRAY型やMAP型を多用しているので Impalaの対応が待ち遠しいです。
実際に使っていく中でまた何か知見が得られましたら、また報告させていただきたいと思います。
弊社ではARRAY型やMAP型を多用しているので Impalaの対応が待ち遠しいです。
実際に使っていく中でまた何か知見が得られましたら、また報告させていただきたいと思います。