皆様こんにちは。サイバーエージェントエンジニアブログ運営委員です。
このたび、サイボウズさんの企画「エンジニア100人に聞きました」に参加させていただきました。
(第一回目の時にサイボウズさんはじめ、一斉に記事を上げていたのが羨ましかったのです…)
「エンジニア100人に聞きました」とは、サイボウズさんのブログから引用させていただくと
>これは、毎回、同じアンケートをそれぞれの企業内で行い、結果を「せーの」で同時公開する、というものです。
>あくまでも「お楽しみ企画」なので、統計学的に有意な結果を得ようというわけではなく、ただ、それぞれの企業カラーを反映した「エンジニアの気風」が見えてきたら楽しかろう、というぐらいのつもり。何より、テクノロジーを愛するエンジニア同士、一緒に面白いことをやって盛り上がれれば、それが一番、というスタンスです。
とのことです!
この企画を通して弊社のエンジニアの雰囲気が伝わればと思います。
それではよろしくお願いします。
それではよろしくお願いします。
今回のテーマは「ながら聴き」です。アメーバ事業本部のエンジニア78名に聞きました。
図中の[]は人数です。
図中の[]は人数です。
では基礎項目からです。
基礎項目は、年齢、性別、初めて使ったコンピュータについて聞いています。
基礎項目は、年齢、性別、初めて使ったコンピュータについて聞いています。
【基礎項目】年齢は?

20、30台が半分くらいずつ在籍中です。
【基礎項目】性別は?

1割が女性エンジニアと言ったところでしょうか
その他がとても気になりますね。
【基礎項目】初めて使ったコンピュータは?

PC互換機が多いですね。
20~30台が中心となるとこんな感じの分布になるのではないでしょうか。
PC9800シリーズ、MSXで入った方も結構多いですね。このあたりの方はおそらく20台ではないと実行委員会は睨んでいます、と思ったら20台の方もいてびっくりしました。
弊社エンジニアの層の厚さというか、濃さというか、何かを感じさせます。
その他のでは様々なマシンをかいていただきました。初めてのマシンはやっぱり印象に残りますよね。
80386の20MHzという、当時ではパワーの有る、、、え、なに?やめて、ちょっと(連れて行かれる)
PC9800シリーズ、MSXで入った方も結構多いですね。このあたりの方はおそらく20台ではないと実行委員会は睨んでいます、と思ったら20台の方もいてびっくりしました。
弊社エンジニアの層の厚さというか、濃さというか、何かを感じさせます。
その他のでは様々なマシンをかいていただきました。初めてのマシンはやっぱり印象に残りますよね。
- X1-turboII
- Z80マイコン。16進キーボードですが何か
- PC-8801
- FM-TOWNS
- ポケコン
80386の20MHzという、当時ではパワーの有る、、、え、なに?やめて、ちょっと(連れて行かれる)
はい、すいません。
それでは、本題の「ながら聴き」についてです。
それでは、本題の「ながら聴き」についてです。
Q1. 仕事のとき、ヘッドフォン等で何かを聴きながら作業することがありますか?

ほとんどの方が聴いていますね。
(Q1であると答えた方)Q2:聴く理由は?(最も大きな理由を1つ)
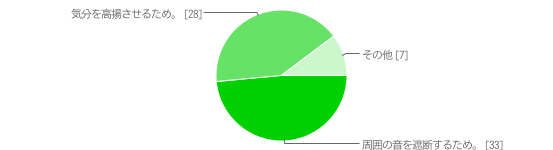
音を遮断するため、気分を高揚させるため、が半分ずつでした。
その他には
- 気分転換
- 眠気防止
- No Music No Life
という意見もありました。
最後の方はミュージシャンって事でいいですね?
(Q1であると答えた方) Q3: どんなものをよく聴いてますか?(ここ最近で、よく聴いてるものを1つ)

やはりほとんどの方は歌や、インストゥルメンタルな音楽を聞いてる人でした。
が、一部実況動画やラジオなど音楽ではない意見や、無音(ノイズキャンセル機能だけオン)という人もいました。
実況動画は頭が色々こんがらがりそうです。
(Q3で 音楽を選んだ方)Q3-1:もしよろしければ、聴いているものを具体的に教えてください。
- Mr. Children
- きゃりーぱみゅぱみゅ
- perfume
- ボカロ
- ドラクエBGM
- ロマンシングサガ・バトルメドレー
- ロック
- ジブリオーケストラ
- HipHop
- R&B
など音楽ジャンルほぼ全部出てきました!
また、インターネットサービスを利用しているという人も少なくなく、
また、インターネットサービスを利用しているという人も少なくなく、
- ニコニコ動画
- ネットラジオ(radiko.jpなど)
という意見もありました。
(Q1であると答えた方)Q4:これを聴くと「はかどる!」、あるいは、ここぞというときに聴くものがあれば、教えてください。
- マクロスFの劇場版アルバム
- RPGのボス戦メドレー。しょぼい作業でも世界を救っている気分になれます。
- クラシック
- メロコア・スラッシュメタル
- 美少女ゲームソング
- モーニング娘。
- マジLOVE2000%
テンポの良い曲、アニメ、ゲームの曲が目立ちました。
(Q1であると答えた方)Q5:何で聴いていますか?
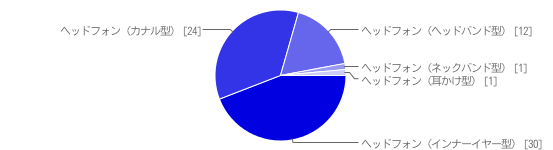
量販店の売り場を見てると最近はカナル型ヘッドフォンが主流になってきたと思っていましたが、インナーイヤー型を使用する人が多いのですね。
(Q5を答えられた方)Q5-1: 使用機器のこだわりポイントがあれば、ぜひ
メーカー指定系のこだわり
- オーディオテクニカ "CK70Pro"
- SONYのスタジオ用ヘッドホン
- iPhone付属のイヤホン
- BOSE
- ビルの1Fのコンビニで売っているPanasonicのもの
機能のこだわり
- bluetooth
- ノイズキャンセル機能
- 音漏れしないこと
かと思えば
- 周りの音を遮断しすぎない
という意見も…。
あとは、
あとは、
- 話しかけられても聞こえないふりができる感じの見た目
確信犯がここにいました!いましたよ!
(Q1であると答えた方)Q6: 「ながら聴き」によるエピソードがあれば教えてください。
ノっちゃった系
- 「頭が揺れてる」とよく言われる
- 気付いたら歌っていた
- 気付いたら踊っていた
- 気付いたら終電を逃していた
聞こえなかった系
- 先輩からの声掛けを無視する
- ふと横に部長がいて何かしゃべってたけど聞き取れず
失敗系
- PCにヘッドホンがちゃんと刺さっていなくて、実はフロアに音が響いてた
つっこもうにも、ずうずうしい人なのか天然なのか判断しずらいですね。。
その他
- プレーヤーを止めるまでヘッドホンを外せない
- 歌ってしまってるんじゃないのかという不安
エンジニアは繊細なのです…。
(Q1で "ない" と答えた方)Q7:「聴かない」あるいは「聴かなくなった」理由は?

逆にノリすぎて集中できなくなりそうな時は聴かないという選択肢もありですね。
(Q1で "ない" と答えた方)Q8:仕事場で「ながら聴き」をしている人を見て、どう思いますか?

急ぎでない話はスカイプやIRCを使う方がコストが低いので、あまり直接話しかけなくなりました。
今回たくさんのエンジニアから回答が集まり、様々な意見が出ました。
仕事の仕方も人それぞれですね。
いかがでしたでしょうか?
本アンケートは一斉公開なため、まだ他社さんの結果を全く知りません。
他社さんの結果も気になりますね!