そんな中、日本代表とも言うべき楽天の椎葉さん (@bufferings) が堂々たるプレゼンを全編英語で披露されていました。タイトルは DDD+CQRS on Spring Cloud で、導入からまとめまで話の流れも素晴らしく、スライドも手作り感溢れる手書きスライドを披露し、プレゼン終了後は会場から拍手喝采でした。かっこ良すぎる!
M. Murase, M. Takano, R. Suzuki, and T. Arita, "A statistical analysis of play data in a social network game: Effects of communication on cooperative behavior", 31st International Congress of Psychology (ICP2016), Poster Presentation in Japanese, RC-05-2, 2016.
Data Microservices というデータに着目したマイクロサービスアーキテクチャを、Spring Cloud Data Flow と Spring Cloud Stream を使って実現するというセッションでした。
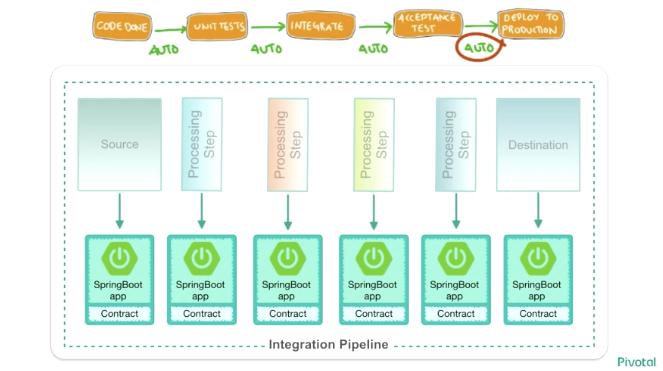
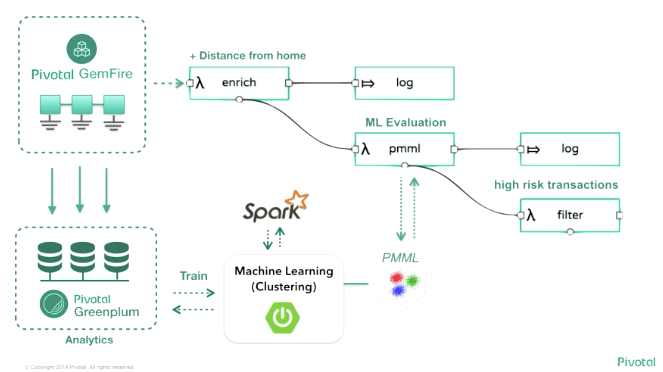
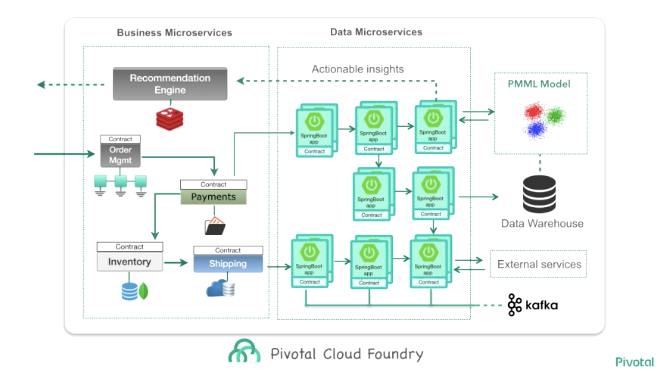
Data Microservices は、このセッションだけでなく他のセッションでも頻繁に聞かれたキーワードでしたが、このセッションで Data Microservices とはどんなものかイメージすることができました。マイクロサービスアーキテクチャと聞いてよくイメージされる、モノリシックなアプリケーションを分割したシステム的なアーキテクチャのコンセプトを、データ処理のプロセスも同じように適用します。モノリシックな1枚岩のデータ処理プロセスではなく、小さいプロセスを組み合わせることで、データを加工するプロセスをより迅速に開発し、リアルタイムにユーザに分析結果をフィードバックできるように、というのが Data Microservices のコンセプトだと思います。
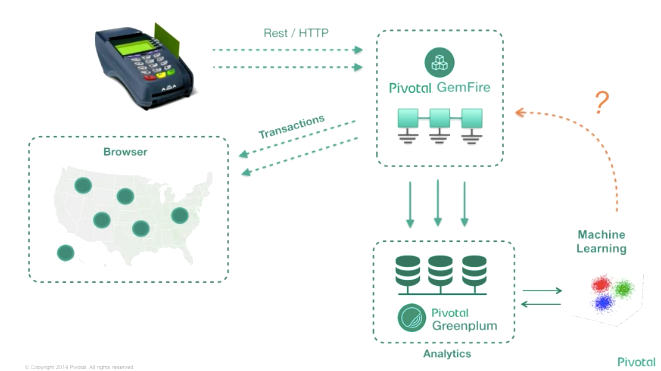
コンウェイの法則で語られるように組織ごとにマイクロサービス化が進んでいっても、連携するシステムは相変わらずモノリシックだったり巨大なシステムが残り、それらを Integration Bus や ESB(Enterprise Service Bus) などで繋ぎ、ETL ミドルウェアで集約しデータ・ウェアハウスなどに蓄積するのが典型的なデータ分析のアーキテクチャですが、これは高価なソリューションであることが多く、また、夜間バッチなどで頑張って計算を行っているのが実情で、夜間バッチが遅れたりすれば分析業務にも影響が出ますし、リアルタイムな分析や機械学習は難しいという問題があります。
そしてこれらをクラウド上で実現することで、メトリクスやモニタリング、ログの集約やオートスケーリング、自動回復なども実現できるとも付け加えていました。また、データ処理パイプラインを Spring Cloud Data Flow を使って定義することで、それぞれのデータ処理プロセスをオーケストレーションすることができるようです。
各国のエンジニアたちもクロスブラウザでのHLS(HTTP Live Streaming)再生に疲弊しているようで、デンマークから来たエンジニアはその場で1時間くらいmanguiさんにWebVTTの質問をしていました。
所感
知らないことが多かった
今回このIBCに参加して心に残ったことは自分の知らない発見がたくさんあったことでした。映像という分野において4K、HDR、VRなどの技術をどうWebの中で表現していくか注視していきたいと思います。またOTTの台頭によってインターネット動画の機運が世界的に急速に高まっていることも身にしみて感じました。Image may be NSFW. Clik here to view.
Material Design を使ったマルチデバイスに対応するデザインの作り方(Google:鈴木 拓生)
現在、様々なデバイスでWEBページを表示できるが、デバイスによって見た目がバラバラでユーザー体験が統一化されていないのを解決するために「Material Design」というデザインフレームワークが誕生したというお話の後、Device metrics, Resizer, といったMaterial Designの考えを組み込んだレイアウトを考えるためのツールや Google Fonts, Noto Fonts, Material Icons, といったフォントやアイコンなども紹介してくれました。
そんな中、日本代表とも言うべき楽天の椎葉さん (@bufferings) が堂々たるプレゼンを全編英語で披露されていました。タイトルは DDD+CQRS on Spring Cloud で、導入からまとめまで話の流れも素晴らしく、スライドも手作り感溢れる手書きスライドを披露し、プレゼン終了後は会場から拍手喝采でした。かっこ良すぎる!
M. Murase, M. Takano, R. Suzuki, and T. Arita, "A statistical analysis of play data in a social network game: Effects of communication on cooperative behavior", 31st International Congress of Psychology (ICP2016), Poster Presentation in Japanese, RC-05-2, 2016.
Data Microservices というデータに着目したマイクロサービスアーキテクチャを、Spring Cloud Data Flow と Spring Cloud Stream を使って実現するというセッションでした。
Data Microservices は、このセッションだけでなく他のセッションでも頻繁に聞かれたキーワードでしたが、このセッションで Data Microservices とはどんなものかイメージすることができました。マイクロサービスアーキテクチャと聞いてよくイメージされる、モノリシックなアプリケーションを分割したシステム的なアーキテクチャのコンセプトを、データ処理のプロセスも同じように適用します。モノリシックな1枚岩のデータ処理プロセスではなく、小さいプロセスを組み合わせることで、データを加工するプロセスをより迅速に開発し、リアルタイムにユーザに分析結果をフィードバックできるように、というのが Data Microservices のコンセプトだと思います。
コンウェイの法則で語られるように組織ごとにマイクロサービス化が進んでいっても、連携するシステムは相変わらずモノリシックだったり巨大なシステムが残り、それらを Integration Bus や ESB(Enterprise Service Bus) などで繋ぎ、ETL ミドルウェアで集約しデータ・ウェアハウスなどに蓄積するのが典型的なデータ分析のアーキテクチャですが、これは高価なソリューションであることが多く、また、夜間バッチなどで頑張って計算を行っているのが実情で、夜間バッチが遅れたりすれば分析業務にも影響が出ますし、リアルタイムな分析や機械学習は難しいという問題があります。
そしてこれらをクラウド上で実現することで、メトリクスやモニタリング、ログの集約やオートスケーリング、自動回復なども実現できるとも付け加えていました。また、データ処理パイプラインを Spring Cloud Data Flow を使って定義することで、それぞれのデータ処理プロセスをオーケストレーションすることができるようです。
各国のエンジニアたちもクロスブラウザでのHLS(HTTP Live Streaming)再生に疲弊しているようで、デンマークから来たエンジニアはその場で1時間くらいmanguiさんにWebVTTの質問をしていました。
所感
知らないことが多かった
今回このIBCに参加して心に残ったことは自分の知らない発見がたくさんあったことでした。映像という分野において4K、HDR、VRなどの技術をどうWebの中で表現していくか注視していきたいと思います。またOTTの台頭によってインターネット動画の機運が世界的に急速に高まっていることも身にしみて感じました。Image may be NSFW. Clik here to view.
Material Design を使ったマルチデバイスに対応するデザインの作り方(Google:鈴木 拓生)
現在、様々なデバイスでWEBページを表示できるが、デバイスによって見た目がバラバラでユーザー体験が統一化されていないのを解決するために「Material Design」というデザインフレームワークが誕生したというお話の後、Device metrics, Resizer, といったMaterial Designの考えを組み込んだレイアウトを考えるためのツールや Google Fonts, Noto Fonts, Material Icons, といったフォントやアイコンなども紹介してくれました。